逻辑内存和物理内存
计算机的物理内存(physical memory, RAM) 是一个包含了以字(word)为储存单元的硬件。“字”是一个固定的数据大小单位,通常来说1字 = 4字节(见下表)。物理地址(physical address)是一个字在内存为n的空间中的位置。
| 数字 | 单位 | = | 数字 | 单位 |
|---|---|---|---|---|
| 1 | 字 | = | 4 | 字节 |
| 1 | 字节 | = | 8 | 比特 |
一个逻辑地址空间(logical address space)是物理内存的抽象,它包含了一段从0到m - 1的抽象内存地址,其中m为逻辑空间地址的大小。一个逻辑地址是对在逻辑空间0 到 m - 1之间所有字的标示。

如上图,在硬件层面,我们有内存,内存里面会分配0到14的空间大小(以字为单位)。还记得复习一我们说过的虚拟化吗?操作系统给每个程序虚拟了一个逻辑空间地址,它们都从0开始。因此,逻辑地址空间是不存在的,这些程序的数据其实储存在磁盘中。这么做有几个好处
- 如果没有这一层逻辑空间,进程直接在物理内存中进行读写操作,这样会导致安全隐患,因为进程和进程之间没有一个隔离措施。通过逻辑分区,进程之间互相不知道对方的存在,保证了进程的安全。
- 有了这一层逻辑空间,操作系统可以将那些长期没有使用的进程保存放回到磁盘中,这样便可以更加高效地调度进程对内存的使用(你看图中,进程1也不是一定要连在一起的)。
- 通过虚拟化,用户不需要自己设计和考虑内存的使用。进程会以为自己实际访问的就是内存空间,并且这个内存空间对进程来说是无限大的。
程序的转换
源码模块(source module)是一个用编程语言写出来的程序,或者说是程序的元件,它必须要通过编译器或者解释器来转换成可执行的机器码。
目标模块(Object module)是源代码通过编译后得到的机器语言。一个目标模块可以单独运行,也可以和其他模块,使用链接器^1链接起来放到一个加载模块中。
加载模块(load module)是一个或多个组成的程序,它可以被加载到内存并执行。

重定位和地址绑定
由于程序的物理地址在其被送进加载模块之前都无法确定, 编译器和链接器假定逻辑地址空间从0开始。在程序转换的每个步骤中, 指令中出现的逻辑地址和数据都可能会被改变。只有在最后一个步骤的时候的,程序加载才能被绑定到它的物理地址上。
程序重定位(relocation)是将程序某个部分从一个地址移到另一个地址的过程。重定位可以是逻辑地址和逻辑地址之间的转换,也可以是逻辑地址和物理地址之间的改变。
静态重定位(static relocation)是指在进程被执行之前,将所有的逻辑地址绑定到物理地址。
动态重定位(dynamic relation)延迟逻辑地址到物理地址的绑定,直到这个部分的代码需要被执行。
比如说有一段代码
1 | mov R1, 200 |
它被加载之后,在静态重定向下,当程序被加载到内存之后,该地址将会被翻译成被分配到的物理地址。这叫静态重定位
1 | mov R1, 1200 |
而动态重定向则不改变这部分代码,而是执行的时候进行翻译。
动态重定向的实现
CPU中可以用寄存器重定向。大多数程序都由三个部分组成:代码,静态数据,动态数据。一个简单的内存管理方法是将这三部分当作一个整体来看,也就是说将他们放在相邻的内存空间中。动态重定向可以通过用一个重定向寄存器来实现,它的值是程序第一行代码的内存地址。寄存器的地址会在后面执行其他部分代码需要寻址的时候被调用。

我们看上面这个例子,内存中有一个进程。在某一时刻,它被分配到内存500的位置,所以我们的重定向寄存器(Relocation Register)是500。当我们做load R1, 100这个操作的时候(将100这个逻辑地址的值传给R1),它实际获取的内容是在物理内存空间(RR+100) 600 的位置的内容。过了一会儿,内存通过调整,将该进程放在了100的位置,在进行load R2, 20的时候则是加载地址为(100 + 20)的数据。
另一个更灵活的方法是将三个部分分开,每个部分放在不同的内存地址。然后使用三个重定向寄存器来分别记录这三个部分代码的位置。
空闲空间管理
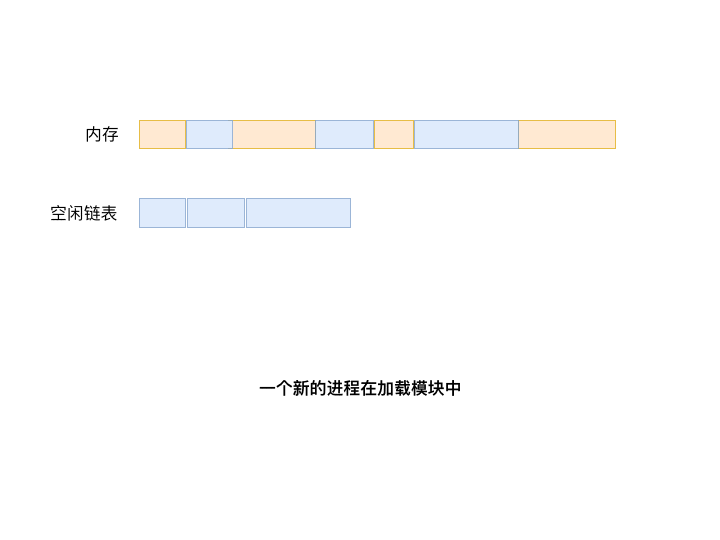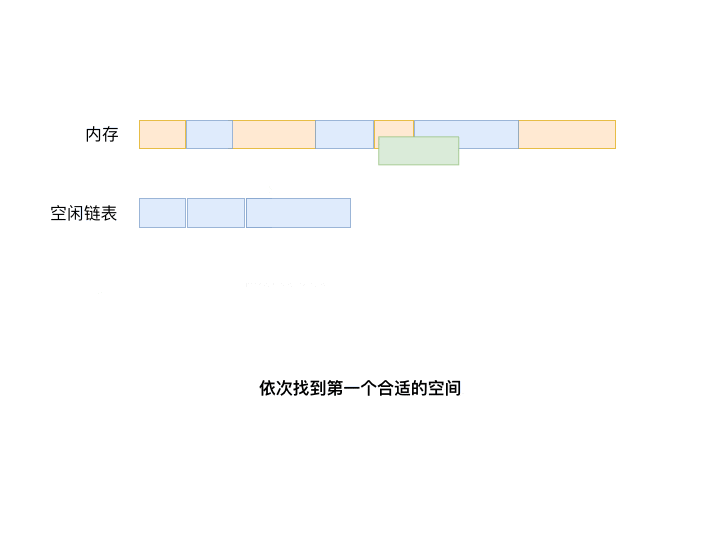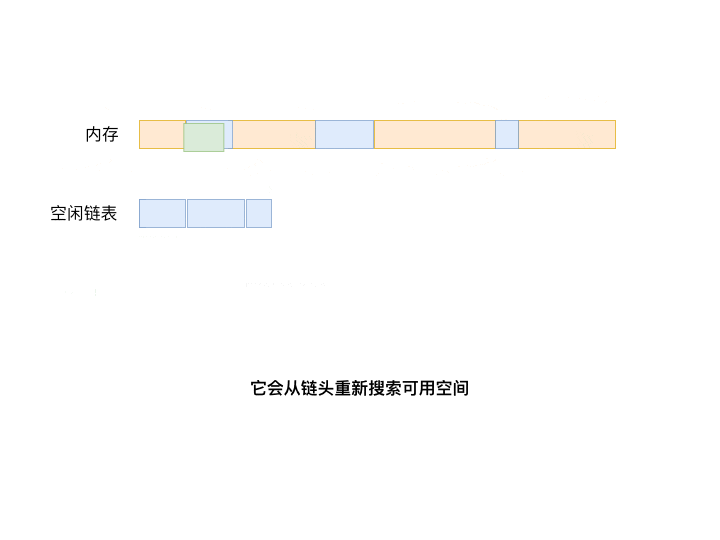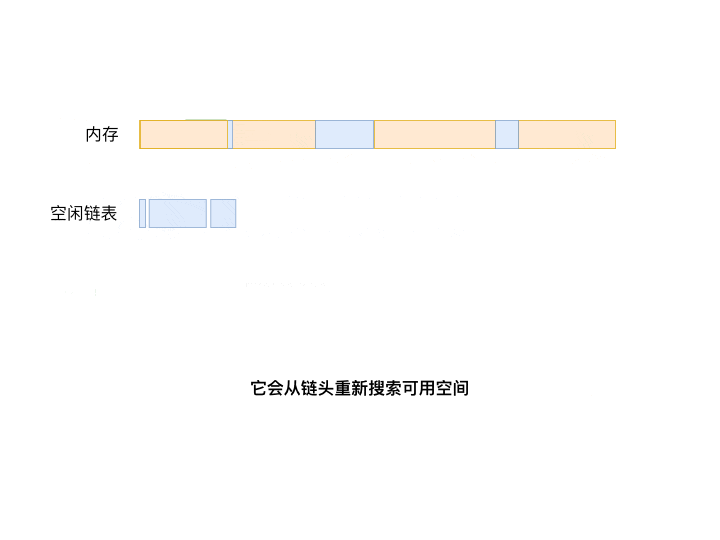
随着进程的运行和保存,也因为内存空间有限,它们会被不停的进出移动。如果无法将整个内存空间充分利用将十分可惜。另外某些进程在执行到一定的程度需要更加多的空间,这个时候系统要将其挪到更大的空槽内, 我们称这些空槽为自由分区(hole)。所以一个操作系统要监测内存空间的使用情况。通常来说,当一个程序需要加载到内存的时候,操作系统会用一个链表来找到最好的自由分区给程序。我们称那个保持跟进自由分区的链表为空闲链表

上图展示了一个程序P通过空闲链表寻找可用空间
有多个为程序寻找内存空间使用的方法:
首次适应算法
首次适应算法(First fit)永远从链表第一个元素开始搜索,直到找到第一个能满足进程大小要求的自由分区为止。
循环首次适应算法
相比首次适应算法从开头搜索起, 循环首次适应算法(Next fit)从上次分配空间的位置开始搜索。

最佳适应算法(Best fit)
该算法遍历整个链表来找到可以被程序使用的最小自由分区。
最坏适应算法(Worst fit)
该算法和最佳适应算法相反,总是找最大的自由分区给程序使用。
注意:每次进程加载到内存中后,空闲链表会自动调节
管理内存不足
内存碎片和50%法则
外部内存碎片(external memory fragmentation)是指由于自由分区很小,但是数量大,导致的可用内存空间不足。如下图,由于每个空闲块都十分小,程序P无法加载到内存中;但实际上如果内存规划合理,P是可以加载到内存中的。

50%法则是指如果寻找一个刚好合适的空间位置给加载的程序的概率无限趋近于0,三分之一的内存空间会是自由分区,剩下的三分之二则是被其他程序使用的空间。这个预测有波动,折合一下就是
$$自由分区的数量=0.5\times被利用的内存空间块$$
也就是说,内存中每出现一个自由分区就有两个被利用的内存空间。
交换和内存压缩
当没有一个自由分区的大小能被加载进来的程序使用,有两个解决方案
- 交换(swapping): 暂时地将某个程序块挪出内存空间。这个程序会被保留在磁盘中,一段时间后再将其挪回来。
- 内存压缩(memory compaction):内存压缩是利用一套系统性的方式来挪动内存中的块。通常来说,这个挪动一般都是往一个方向的,这样就能将一部分模块拼成一个大的,给剩下的自由分区留出更大的空间。
共享模块
在上面的加载模块中,我们说到,很多程序会被通过链接器来合成一个大的程序块。这个网站详细介绍了这一过程。比如说C语言的标准库里面提供了一个标准输出库,一个简单的hello world程序就需要跟它一起被链接器连接起来使用。为了能够充分地利用内存空间,内存管理中引入了一种共享机制。当多个程序都需要用到某个模块的时候,系统会允许他们调用同一个模块。
分页
页(page)是一个固定的,临近两个逻辑地址之间的块。
**页框(page frame)**是一个固定的邻近两个物理地址之间的块,它被用一个数字表示。页框是内存管理中数据的最小单位。
分页表(page table) 是一个用于记录在逻辑地址中的页以及它们所映射的,内存地址中的页框的一个数组。

逻辑地址和物理地址
地址空间的的大小是$2^{n}$的形式存在的,其中n是能够完整利用地址的比特。当地址空间被分割成一个个页的时候,页的大小就是$2^{k}$,其中k是可以代表每个字的比特。剩下的n-k个比特确定了页的数量:2^{n-k}。
通过将内存地址分割成两部分,通常来说第n-k个比特是页号,剩下的k个比特是用来表示该页的位移w。
假设我们的地址是64位的,我们将会需要六位二进制的数来表示内存地址$(2^{6}=64)$。假设页的大小为8,我们将会需要3位比特来记录位移$(2^{3}=8)$。剩下的三位比特将会用于记录页号。

注意上图所写的P1, P2, P3并非进程process, 而是page。取决于分页的方式,逻辑内存的页号可能会映射到物理内存中不同的位置,但是每页的位移总是一样的。

上图中页号111被映射到页框0111中,但是位移总是000-111之间。
地址映射
操作系统需要将逻辑内存地址(p, w)匹配到物理内存地址(f, w)上。其中p和f分别代表页和页框, 代表位移。从逻辑内存映射到物理内存需要经过以下步骤。
- 获取一个逻辑地址(p, w), 从分页表中找到p
- 读取p所对应的页框f
- 结合f以及位移w来找到对应的物理地址(f, w)
内部碎片化和边界监测
分页式储存规定了页和页框的大小一致,这样所有的页都可以找到对应的页框,而不至于产生页外的自由分区。这样一来就可以避免外部碎片化的产生了。但通常来说储存空间只允许一种大小的页存在,当页不能被用满的时候就会产生内部碎片化(Internal fragmentation)。
出于安全考虑,当我们程序被加载到内存中时,或者需要进行地址转换的时候,要保证一个程序的地址不会超出它的边界。

上图展示了一个程序占用了3个页,其中第三个页只有部分被使用了(内部碎片化)。操作系统必须保证这个程序能够访问的空间只能是page1,page2以及page3边界(虚线)的前半部分。
分段和分页
分页式储存中,所有程序的代码,数据,栈,以及其他数据结构都被放在了相连的一组页中。程序的每个部分的大小是不一样的,各个部分的边界和页的边界不完全一致。比如上面这个程序的边界在011, 001而页边界则是在 011, 111。因为两者的边界不一致,逻辑空间中程序间的分享和保护讲得不到保证。
分段(segment)便是用于解决这种问题的一个方法,它会给每个进程提供可变的逻辑空间。相对应,分段也需要一个分段表(segment table)来实现逻辑内存和物理内存之间的映射。

地址转换
跟分页一样,分段式储存将每个逻辑地址分成两部分。操作系统需要转化一个虚拟地址到物理地址需要以下步骤
- 输入一个逻辑地址(s, w)。
- 在分段表中找到位移s,然后找到对应的物理段sa及其大小sze。
- 如果$w>sze$就拒绝该地址的请求。
- 否则就访问对应的(sa, w)
分段+分页
分段式储存的好处是可以创建多个可变的地址空间,而分页的优势是可以在内存中将任意页放到页框中。为了能够互取所长,我们可以将两种方式合并起来用。
逻辑地址空间包含多个可变的段,但是每个段被分割成大小一样的页中。和单独使用分页或者分段不同,这次我们要将地址分成三个部分:段号,页号,和位移 (s, p, f)。一个物理地址还是一样被分成两个部分,框号和位移(f, w)
每个进程都有一个分段表,每一行是一个对应的分页表。操作系统要转换一个地址将要做以下操作:
- 输入一个逻辑地址(s, p, w), 用分段表来找到对应的分页表。
- 如果分页表上(p, w)比分段的大小还要大,那么就拒绝访问。
- 否则访问该分页表来找到(p, w),然后利用p找到物理内存的页框f。在该页框中寻找位移w。
这种结合两种方式进行的储存管理方式被称为段页式储存管理^2。
地址转换的备用缓存
分页也好,分段也罢。它们都要经常用到分段表和分页表来频繁的读写内存信息。这个转换的过程必须要高速地运行才能流畅地运行程序。于是转译后备缓冲区(Translation lookasie buffer, TLB)^3被发明出来了。这是一个高速的关联储存模块,他被用于记录最近的地址转译。当一个逻辑地址(s, p, w)被转译成物理地址(f, w), 转移后备缓冲区会将这个两个地址对应保存起来。当另一个地址需要被访问,它有着和前一个地址相同的段和页的时候,TLB会找到已保存的段页,并且加上新的位移w‘变成(s, p, w’)来访问改地址。